VLUE
VLUE: A Multi-Task Multi-Dimension Benchmarkfor Evaluating Vision-Language Pre-training
Wangchunshu Zhou, Yan Zeng, Shizhe Diao, Xinsong Zhang
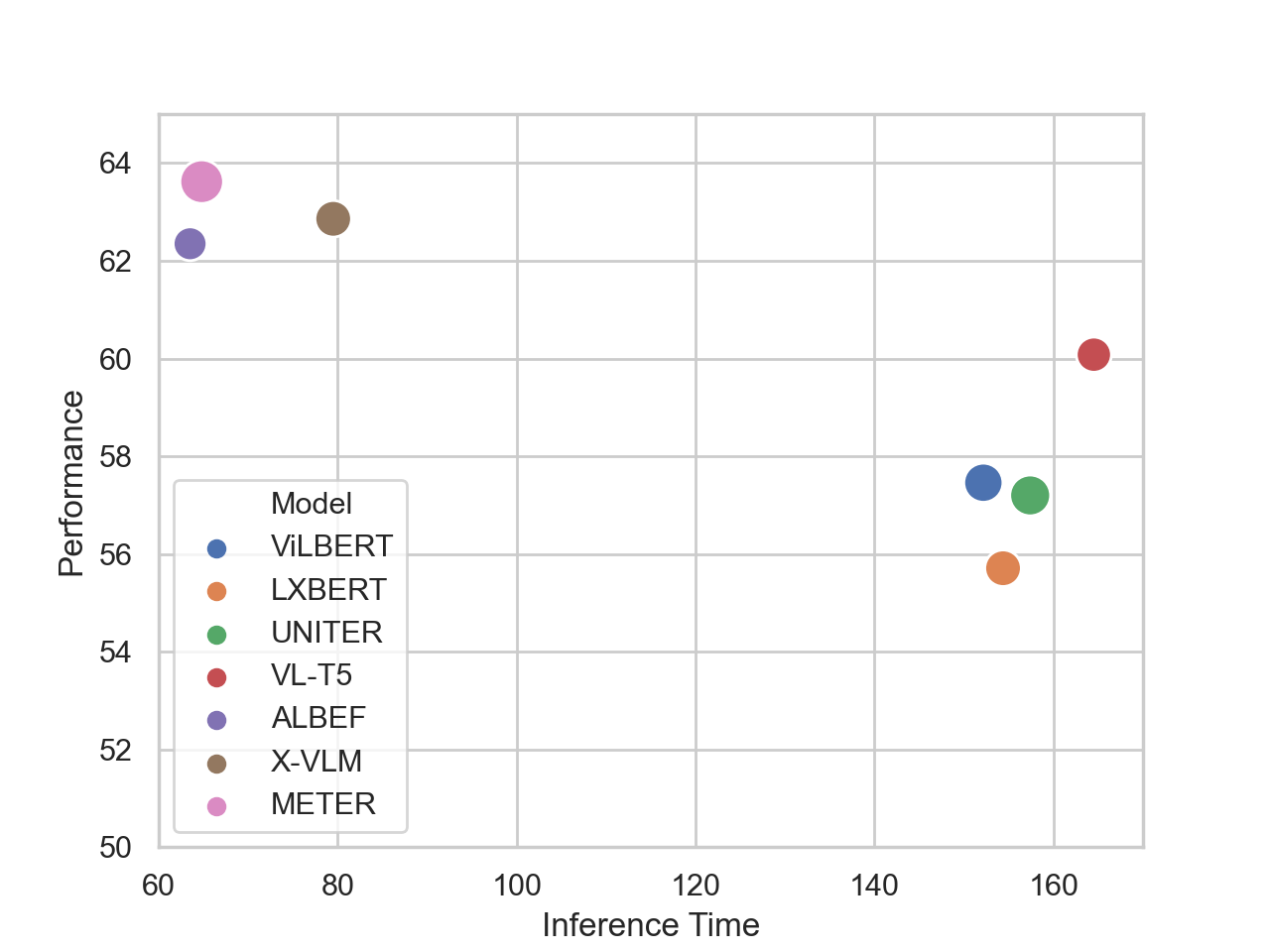
We present the Pareto front in terms of the efficiency-performance trade-off of VLP models. The performance of considered VLP models is measured by the mean accuracy on NLVR2 and VQA test sets. We measure the efficiency of VLP models by their average inference time on these test sets. Note that for models requiring object detection to extract features from the raw images, we include the object detection time in the total inference time. We fix the hardware environment to 1 Nvidia Tesla V100 GPU and the batch size to 1 to simulate real application scenarios. We can see that models with similar performance may have completely different positions in the Pareto front of efficiency-performance trade-off. For example, VL-T5 performs only marginally worse than ALBEF, but requires an average inference time 2.4 times longer than ALBEF. Therefore, ALBEF should be considered to significantly outperform VL-T5 in the dimension of efficiency-performance trade-off. This further demonstrates the necessity of a multi-dimension benchmark like VLUE for more throughout comparisons.
@article{zhou2022vlue,
author = {Wangchunshu Zhou and Yan Zeng and Shizhe Diao and Xinsong Zhang},
title = {VLUE: A Multi-Task Benchmark for Evaluating Vision-Language Models},
journal = {CoRR},
volume = {abs/2205.15237},
year = {2022},
archivePrefix = {arXiv},
eprint = {2205.15237}
}